Priorisierung und Annotation der Dimensionen der Eingabedaten sind Teil des optionalen Vorbereitungsschritts für jede Analyse, wie in Arbeit mit Inspirient > Vorbereitung der Analyse vorgestellt. Sowohl für Dimensionsprioritäten als auch für Annotationen werden vom System auf der Grundlage seines aktuellen Verständnisses des Datensatzes vorgeschlagene Werte bereitgestellt. In den meisten Fällen müssen die Benutzer diese Vorschläge nur überprüfen und möglicherweise anpassen. Wenn eine Analyse über die Schaltfläche I’m feeling lucky gestartet wird, werden alle Vorschläge direkt verwendet, ohne dass sie vom Nutzer gesichtet und explizit bestätigt werden müssen.
Priorisierung der Dimensionen des Eingabedatensatzes
Die Priorisierung wirkt sich auf die Sortierreihenfolge der Ergebnisse aus, so dass Ergebnisse, die von Dimensionen mit höherer Priorität abgeleitet sind, in den Ergebnissen prominenter angezeigt und eher in die Stories aufgenommen werden.
Mit Prioritäten wird sichergestellt, dass die Vollständigkeit der Ergebnisse über alle Analysemethoden hinweg auch bei sehr großen Datensätzen nur kontrolliert abnimmt. Die genauen Auswirkungen niedriger/hoher Prioritäten sind wie folgt:
- Dimensionen, die auf die niedrigste Priorität eingestellt sind, werden bei der Analyse ignoriert
- Dimensionen mit der höchsten Priorität werden bevorzugt analysiert, d.h. sie werden garantiert von allen anwendbaren Analysemethoden ausgewertet
- Andere Niedrigprioritätsdimensionen können bei bestimmten Analysemethoden ausgelassen werden, wenn andernfalls die Berechnungsanforderungen die zugewiesenen Ressourcen übersteigen würden.
Kunden- und hardwarespezifische Optionen können von Systemadministratoren eingestellt werden, um das Systemverhalten fein abzustimmen.
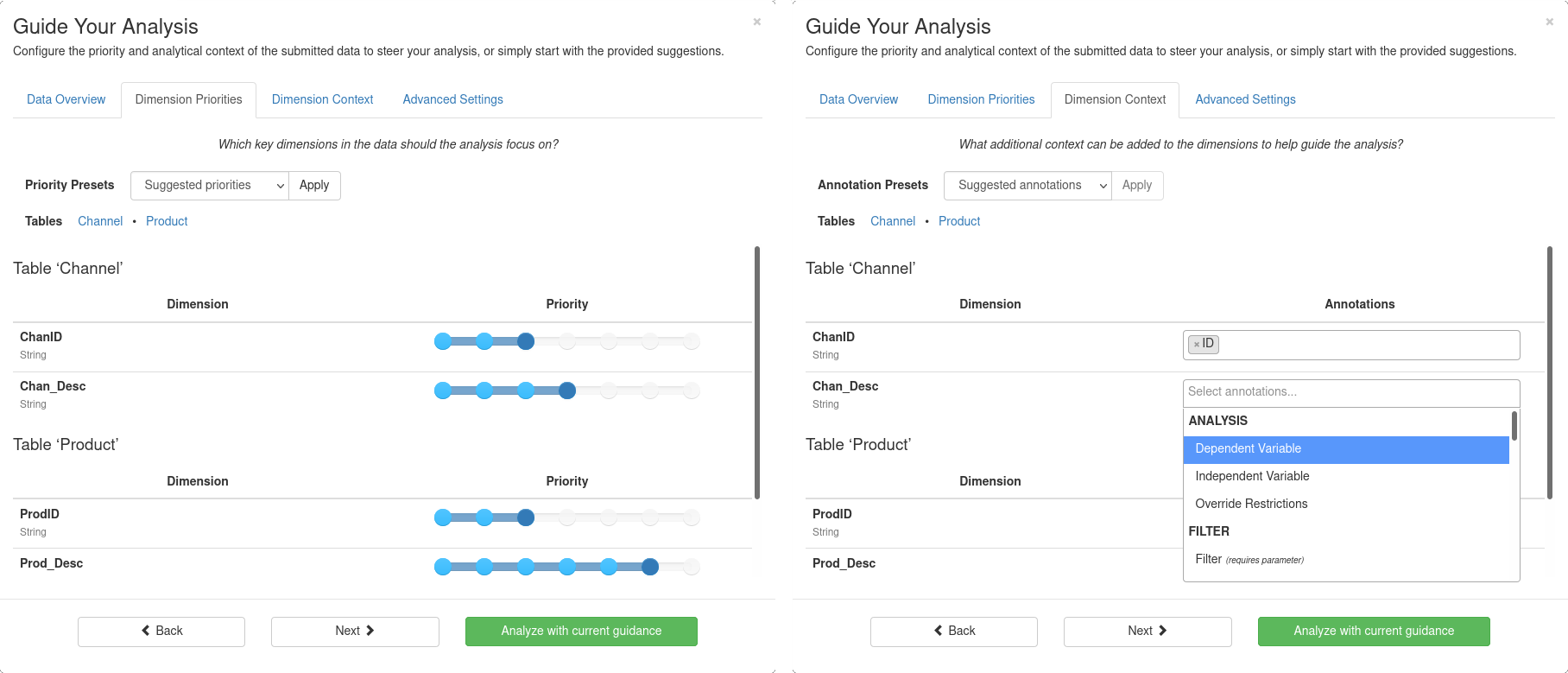
Kontextualisierung der Dimensionen des Eingabedatensatzes
Mit Hilfe von Annotationen können Nutzer den analytischen Kontext von Eingabedimensionen festlegen, z.B. ob die Berechnung der Summe über eine Spalte numerischer Werte sinnvoll ist (z.B. bei Bestandsmengen) oder nicht (z.B. bei Zeitreihenmessungen).
Es gibt vier Arten von Datenannotationen:
- Filter – Annotationen, die verschiedene Filter auf die Eingabedaten anwenden
- Transformation – Annotationen, mit denen eine Transformation der Eingabewerte durchgeführt wird
- Semantik – Annotationen zur expliziten Übermittlung der Spaltenbedeutung
- Analyse – Annotationen, die die Analyse beeinflussen
Die vollständige Liste der unterstützten Annotationen und ihre Auswirkungen sind in der folgenden Tabelle aufgeführt.
| Annotation | Art | Beschreibung | Details |
|---|---|---|---|
FILTER_ON |
Filter | Filterung der Eingabetabelle nach einem bestimmten Kriterium (regulärer Ausdruck akzeptiert) | |
FILTER_ON_DOMINANT_DOMAIN |
Filter | Filtert die Tabelle nach den am häufigsten vorkommenden Elementen (80 % des Vorkommens) | |
FILTER_ON_DOMINANT_DOMAIN_BY_VALUE |
Filter | Filtert die Tabelle auf die Elemente mit der größten Summe einer bestimmten Wertespalte (80% des kumulierten Wertes) | |
FILTER_ON_TOP_3_BY_VALUE |
Filter | Filtert die Tabelle auf die 3 Elemente mit der größten Summe einer bestimmten Wertspalte | |
FILTER_ON_TOP_10_BY_VALUE |
Filter | Filtert die Tabelle auf die 3 Elemente mit der größten Summe einer bestimmten Wertspalte | |
ABC_CLASSIFICATION |
Transformation | Einteilung der Spalte in n Kategorien mit Hilfe der ABC-Analyse | |
ANONYMIZE |
Transformation | Anonymisierung von Elementen in einer Spalte mit einem generierten ID-Wert | Annotiert eine zu anonymisierende Dimension, indem sie durch eine neue Spalte ersetzt wird, die einen kryptografisch sicheren Hash-Wert für jeden Originalwert enthält. Eine Nachschlagetabelle zur Zuordnung von Hashwerten zu Originalwerten wird dem Benutzer, der die Analyse besitzt, separat zur Verfügung gestellt. |
DEEP_DRILL_DOWN |
Transformation | Aufteilung der Eingabetabelle auf jedes Element in der Spalte | |
DEFAULT_VALUE |
Transformation | Transformiert fehlende Werte, d.h. fehlende oder null, in einen Standardwert | Vermerkt eine Dimension, um einen bestimmten Standardwert zu verwenden, falls kein Wert vorhanden ist, z.B. {DEFAULT_VALUE(no data available)} |
DEFINE_AS_MISSING |
Transformation | Definiert einen Wert, der bei der Analyse als fehlend behandelt werden soll | Dimension beinhaltet einen spezifischen Wert, der als fehlend behandelt werden soll, z.B. {DEFINE_AS_MISSING(-1:nicht anwendbar)} |
DRILL_DOWN |
Transformation | Aufteilung der Eingabetabelle nach den häufigsten Einträgen (80 % des Auftretens) | |
IGNORE_VALUE |
Transformation | Ignorieren angegebener Werte, d.h. als abwesend oder null behandeln | Übergeht bestimmte Werte einer Dimension, indem übereinstimmende Zeilen bei der Analyse ausgeschlossen werden, z.B. {IGNORE_VALUE(John Doe)} |
JOINABLE_ID_VALUES |
Transformation | Verknüpft Tabellen anhand bestimmter ID-Werte | Entsprechend annotierte Dimension kann für die Verknüpfung mit einer anderen Tabelle mit einer entsprechenden JOINABLE_ID_VALUES-Annotation verwendet werden |
USE_AS_IS |
Transformation | Deaktiviert alle automatischen Transformationen während der Analyse für diese Spalte | |
CATEGORICAL |
Semantik | Werte, die kategorische Elemente darstellen | Annotierte Dimension enthält kategorische Werte ohne natürliche Reihenfolge (siehe auch ORDINAL) |
DEMOGRAPHIC_VARIABLE |
Semantik | Soziodemografische Informationen | Dimension, die als soziodemografische Variable zu behandeln ist, z.B. bei der Analyse von Umfragedaten |
HAS_SUBTOTALS |
Semantik | Numerische Spalte mit Zwischensummen | Vermerkt, dass eine Dimension Zwischensummen enthält |
ID |
Semantik | Werte, die ID-Werte darstellen | Annotiert eine Dimension, die als ID-Werte behandelt werden soll |
IS |
Semantik | Werte, die eine ausgewählte Bedeutung repräsentieren | |
LESS_IS_BETTER |
Semantik | Ein niedrigerer numerischer Wert ist besser | Vermerkt eine Dimension, die numerische Werte enthält, für die im Kontext der aktuellen Analyse niedrigere Werte wünschenswert sind |
MAXIMIZABLE |
Semantik | Numerische Werte, bei denen das Maximum für alle numerischen Operationen berücksichtigt werden sollte | |
MINIMIZABLE |
Semantik | Numerische Werte, bei denen das Minimum für alle numerischen Operationen berücksichtigt werden sollte | |
MORE_IS_BETTER |
Semantik | Ein höherer numerischer Wert ist besser | Dimension enthält numerische Werte, für die im Kontext der aktuellen Analyse größere Werte wünschenswert sind |
NATURAL_LANGUAGE_TEXT |
Semantik | Textwerte, die für die Verarbeitung natürlicher Sprache berücksichtigt werden sollten | Dimension, die als natürlichsprachlicher Text behandelt werden soll, und wendet entsprechende Analysemethoden an |
NOT_CATEGORICAL |
Semantik | Werte, die für alle numerischen Operationen berücksichtigt werden sollten | Vermerkt eine Dimension als nicht kategorische Werte enthaltend |
NOT_SUMMABLE |
Semantik | Numerische Werte, die nicht summiert werden können | Vermerkt eine Dimension als nicht mit summierbaren Werten |
ORDINAL |
Semantik | Numerische Werte, die geordnete kategortische Elemente darstellen | Dimension enthält numerische kategorische Werte mit einer natürlichen Reihenfolge (siehe auch CATEGORICAL) |
SUMMABLE |
Semantik | Numerische Werte, die summiert werden können | Vermerkt, dass eine Dimension summierbare Werte enthält |
SURVEY_DURATION |
Semantik | Indikator für Erhebungsdauer | Dimension, die als Indikator für Erhebungsdauer behandelt werden soll |
SURVEY_INTERVIEWER_ID |
Semantik | Interviewer-Identifikator | Dimension, die als Interviewer-ID behandelt werden soll |
SURVEY_META |
Semantik | Umfrage-Meta-Information | Dimension, die als Umfrage-Meta-Information behandelt werden soll |
SURVEY_RESPONSE |
Semantik | Antworten einer Umfrage | Dimension, die als Antworten einer Umfragebe behandelt werden soll |
AGGREGATION_WEIGHT |
Analyse | Gewichtung von Aggregaten nach Werten in dieser Dimension, typischerweise für die Analyse von Umfragedaten verwendet, um Verzerrungen zu verringern | Vermerkt eine Dimension, die als Gewichtungsvariable behandelt werden soll, z.B. bei der Analyse von Umfragedaten |
DEPENDENT_VARIABLE |
Analyse | Eine Eingabevariable von Interesse, die erklärt werden soll | Dimension, die in der aktuellen Analyse als abhängige Variable behandelt werden soll. Wird beim maschinellen Lernen auch als Target oder Label bezeichnet. |
INDEPENDENT_VARIABLE |
Analyse | Eine Kontrollvariable, die verwendet wird, um Auswirkungen auf eine abhängige Variable zu erklären | Vermerkt eine Dimension, die in der aktuellen Analyse als unabhängige Variable behandelt wird. Wird beim maschinellen Lernen auch als Prädiktor oder Feature bezeichnet. |
OVERRIDE_RESTRICTIONS |
Analyse | Analysebeschränkungen zur Leistungsoptimierung deaktivieren | Analysiert eine Dimension ohne jegliche Beschränkungen, welche sonst eine akzeptable Laufzeit bei der Analyse sehr großer Tabellen gewährleisten. Mit Vorsicht zu verwenden! |
Fortgeschrittene Benutzer können diese Annotationen auch direkt in ihre Daten einbetten, indem sie sie an die in geschweiften Klammern eingeschlossenen Spaltenbezeichnungen anhängen, z.B. {SUMMABLE}.
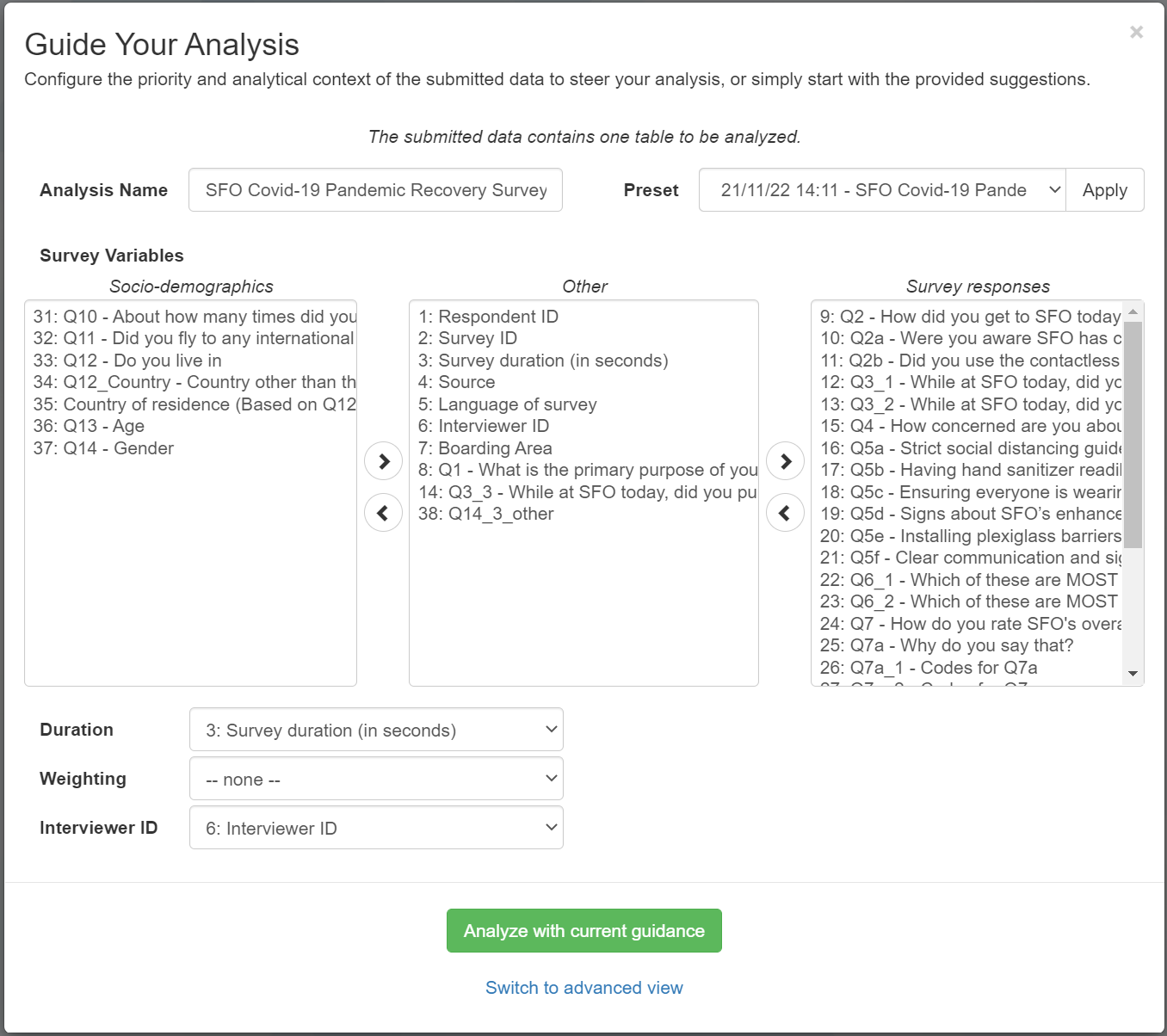
Einfache Analysevorbereitung (Umfrageanalyse)
Mit der Analysevorbereitung, wie oben beschrieben, haben Benutzer vielfältige Kontrolle über die durchgeführte Analyse. Diese potentiell komplexen Anpassungen können jedoch zeitaufwendig sein und sind für manche Benutzer nicht notwendig.
Deshalb bietet Inspirient zusätzlich eine einfachere Analysevorbereitung an, die speziell auf die Umfrageanalyse zugeschnitten ist. In den meisten Fällen gibt dies dem Benutzer genug Kontrolle, um die Analyse mit minimalem Zeitaufwand zu steuern.
Zu Beginn wird dem Benutzer eine vom System erstellte Klassifizierung der Spalten der Eingabedaten angezeigt. Anschließend kann der Benutzer die Klassifizierung nach Belieben anpassen, indem er entweder die Mehrfachauswahl- oder Dropdown-Menüs und die entsprechenden Schaltknöpfe verwendet.
Die Einfache Analysvorbereitung (Umfrageanalyse) wird automatisch für alle Umfrageanalysen angezeigt. Wird eine komplexere Steuerung gewünscht, so gelangt der Benutzer durch einen Klick auf “Switch to advanced view” zur Analysevorbereitung.
Best Practices
- Wenig aber deutlich priorisieren – In den meisten Fällen ist es nicht notwendig, die Prioritäten jeder Dimension eines Datensatzes fein abzustimmen. Es ist zeitsparender, die Prioritäten der wichtigsten Dimensionen schnell anzupassen und dann später Tags zu verwenden, um weniger wichtige Ergebnisse herauszufiltern.
- Selektiv annotieren – Annotationen helfen dem System, die Dimensionen eines Datensatzes in allen Eckfällen korrekt zu behandeln. Das bedeutet, dass in den meisten Fällen die richtigen Analysemethoden angewandt werden, auch ohne Annotationen. Wenn die Zeit drängt, können manche Benutzer sogar einen schnellen ersten Durchlauf mit der Schaltfläche I’m feeling lucky durchführen, die wichtigsten Ergebnisse auf Probleme prüfen und nur die Annotationen hinzufügen, die zur Lösung dieser Probleme erforderlich sind.
- Wiederverwendung bisheriger Prioritäten und Annotationen – Prioritäten und Annotationen aller bisherigen Analysen werden gescannt, um den bestmöglichen Vorschlag für den aktuellen Datensatz zu machen. Dies schließt auch Datensätze von anderen Nutzern (mit Konten auf derselben Inspirient-Dienstinstanz) ein. Die vorgeschlagenen Prioritäten und Annotationen können daher das widerspiegeln, was Ihre Kollegen für Ihre aktuellen Daten für angemessen halten.